Azure AI Speech to Text vs OpenAI Whisper


Azure AI Speech and OpenAI's Whisper model are services that are capable of speech to text transcription not only in the cloud but at the edge too. We do not always entirely need to rely on the use of API keys that authenticate into a cloud-supported inference service all the time.
Let's quickly have a look at Azure AI Speech to Text and OpenAI's Whisper model running locally for inference. Although Azure AI Speech to Text primarily runs as a pure cloud service, it can also be run as what could be called a tethered docker container (we will see why shortly). The OpenAI Whisper model, containing Speech to Text capabilities, can run fully as a docker container and comes in different model sizes to suit various compute capacities and devices. We will be transcribing this 2min 12s long audio clip as a .wav clip in practice (mp3 shown is for illustration only and blog file limitations):
Download the mp3 here (convert to .wav):
Azure AI Speech to Text Container
It should be noted the official Azure AI Speech docker image currently available as a Linux image designed for x64 machines only (it would be nice if there was ARM support 🙂). I will be using a Windows PC running this Linux container.
Some pre-requisites:
- Azure AI Speech Service (Free Tier is fine)- yes, even with a docker container running locally for this, we will require a billable Speech Service in Azure. According to Microsoft, the docker images are not licensed to operate without being tethered back to Azure for metering/billing. It is still possible to run these docker containers completely offline but this requires a permissioned application process where you fill in a form through with Microsoft directly (these are called 'Disconnected Containers').
- Docker Desktop for Windows
With Docker Desktop installed and running on the machine. Use the following command to pull the image:
docker pull mcr.microsoft.com/azure-cognitive-services/speechservices/speech-to-textPull the docker image for Azure AI speech to text
It will take some time to get the image:

Run your container instance with the following as an example, supplying your Azure AI Speech Service API Key and your Speech Service endpoint URL:
docker run -p 5000:5000 --memory 6g --cpus 4 \
mcr.microsoft.com/azure-cognitive-services/speechservices/speech-to-text:latest \
Eula=accept \
Billing={YOUR_ENDPOINT_URI} \
ApiKey={API_KEY}
Logging:Console:LogLevel:Default=InformationSupply your endpoint URL and API key. Also adjust the memory and CPU core allocation based on your machine's capabilities
The container start-up will take a few seconds to complete. After running a container instance and going to your localhost endpoint (localhost on port 5000) you should see this as evidence of the container running successfully:
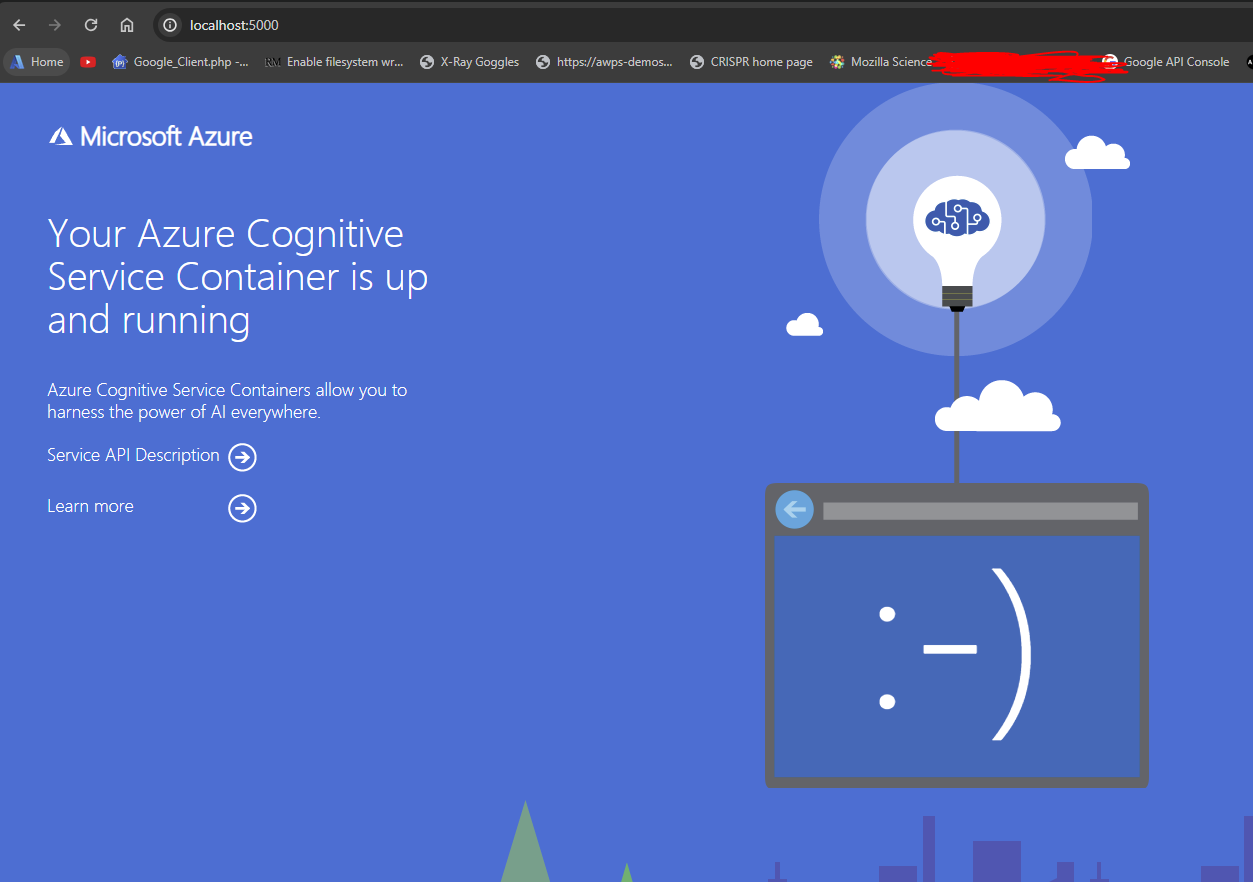
Speech Recognition using local Azure Speech to Text Container
Then to interact with the container in code, we specify the speech service as coming from the localhost on port 5000 instead, compared to how we would do it using the cloud service API key and region, and we carry out speech recognition into text. The following C# code (for .NET8) will work for transcribing long audio where using the RecogniseOnceAsync() method only recognises up to 20s of speech at the time of writing:
using Microsoft.CognitiveServices.Speech;
using Microsoft.CognitiveServices.Speech.Audio;
using System.Diagnostics;
////
var speechConfig = SpeechConfig.FromHost(new Uri("ws://localhost:5000"));
FileStream filestream = new FileStream("{audiosamplePath}", FileMode.Open, FileAccess.Read);
var reader = new BinaryReader(filestream);
var audioInputStream = AudioInputStream.CreatePushStream(AudioStreamFormat.GetWaveFormatPCM(44100, 16, 2));
var audioConfig = AudioConfig.FromStreamInput(audioInputStream);
var recognizer = new SpeechRecognizer(speechConfig, audioConfig);
var stopRecognition = new TaskCompletionSource<int>();
var stopwatch = new Stopwatch();
byte[] readBytes;
do
{
readBytes = reader.ReadBytes((int)filestream.Length);
audioInputStream.Write(readBytes, readBytes.Length);
} while (readBytes.Length > 0);
recognizer.Recognized += (s, e) =>
{
if (e.Result.Reason == ResultReason.RecognizedSpeech)
{
Console.WriteLine(e.Result.Text);
}
};
recognizer.Canceled += (s, e) =>
{
Console.WriteLine($"CANCELED: Reason={e.Reason}");
stopwatch.Stop();
var elapsedSeconds = stopwatch.Elapsed.TotalSeconds;
Console.WriteLine($"Transcription took {elapsedSeconds:0.####} seconds");
if (e.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={e.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={e.ErrorDetails}");
}
stopRecognition.TrySetResult(0);
};
stopwatch.Start();
await recognizer.StartContinuousRecognitionAsync();
Task.WaitAny(new[] { stopRecognition.Task });
await recognizer.StopContinuousRecognitionAsync();
Console.Read();Code for continuously recognising speech from an audio file
With the container running in the background, this is what our code will produce and then displays the time taken to complete inference (68s for a 2min 12s audio clip):
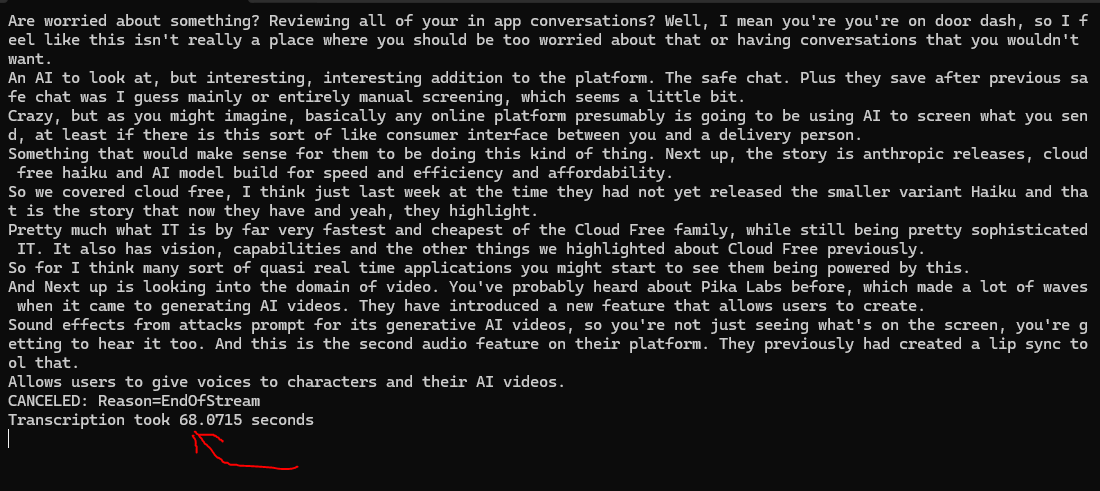
OpenAI Whisper Speech to Text
The Whisper model comes in different sizes as mentioned before. For a standard Windows machine like mine, I'll be selecting the tiny model to execute the transcription. I'll be containerising a small python script and I'll transcribe the same audio as before and getting the transcription at the end. The python script is as simple as follows:
import whisper
import time
#change the model type to your liking based on compute available
#sizes - tiny,base,small,medium,large
model = whisper.load_model("tiny")
def transcribe(audio_path):
start_time = time.perf_counter()
result = model.transcribe(audio_path)
end_time = time.perf_counter()
execution_time = end_time - start_time
print(f"Transcription took {execution_time:.4f} seconds")
print("result is "+ result['text'])
return result['text']
#/app/audio will be mounted onto local host folder. Define the file to transcribe
transcribe("/app/audio/podcastwave.wav")
app.py file for consuming the OpenAI Whisper tiny model given an audio path on the the host machine - /app/audio directory is mounted to a volume on the local machine as we will see later
My dockerfile is as follows:
FROM python:3.10-slim
WORKDIR /app
COPY app.py ./
RUN pip install --upgrade pip
RUN pip install -U openai-whisper
RUN apt-get update && apt-get install -y ffmpeg
CMD ["python", "app.py"] Dockerfile to contain the python script
To build the image, navigate to the local path with the app.py and Dockerfile and execute:
docker build -t whisper-tiny . Docker build will take about 10mins or so
To run the OpenAI Whisper model and start inferencing, you can execute with the following to run a container from the newly built whisper-tiny image:
docker run -p 8000:8000 -v /{your_pathtoWavFile}:/app/audio whisper-tiny
mount the path with the wav file on the host machine
And you get a result fairly quickly with the OpenAI tiny model after it gets loaded (in 13.4s!!!):
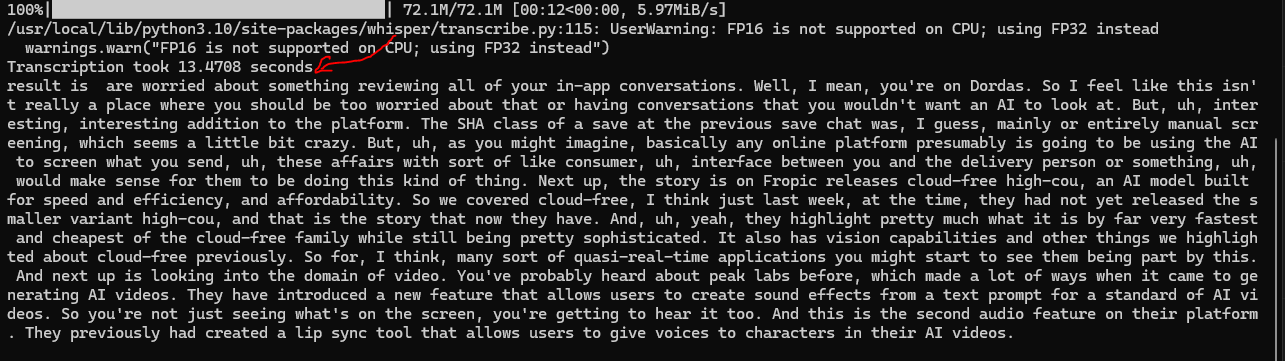
Final Conclusions
The results are in to transcribe a 2min 12s audio clip . The machine used had the following specifications:
-CPU - Intel Core i5 4690k , 4 cores
-RAM - 16GB DDR3
-VRAM(Whisper takes advantage of this) - 2GB Nvidia GTX 960 GPU
Azure AI Speech to Text (allocated 6GB RAM, 4cores) - 68seconds
OpenAI Whisper (using fastest tiny model) - 13seconds!!! 😎
It could be argued that Azure AI Speech was slower due to the lower RAM allocation but I had limitations on my machine as it could barely run anything else at 8GB of memory allocation to the Azure AI Container.