Project Harmony: Azure Functions Fan Out Fan In


The Azure Functions Fan Out Fan In pattern allows Azure Functions to scale and spread a workload across different worker functions that work together in parallel to process a batch of work. The results from each worker function is consolidated into a final result in a separate Function.
In this blog I write about the use of Azure Functions' Fan Out Fan In pattern in order to make use of this cloud scale parallel processing, on a collection of my voice utterances to turn them into text using Azure Speech To Text🛠⚡. These voice utterances in my case are a collection of 765 .wav files stored as blobs in an Azure Storage account.
Pre-Requisites
- Azure Speech Services Resource (Free Tier)
- Empty Blob Storage container to store result (in my case, this is called "outcontainer")
- Blob Storage container to store voice utterance files (in my case, this is called "voice")
- Visual Studio 2022 for deploying Azure Function App to Azure and development
- A number of voice utterances as .wav files uploaded to the target storage container in Azure (uploaded to "voice" container)
The Architecture
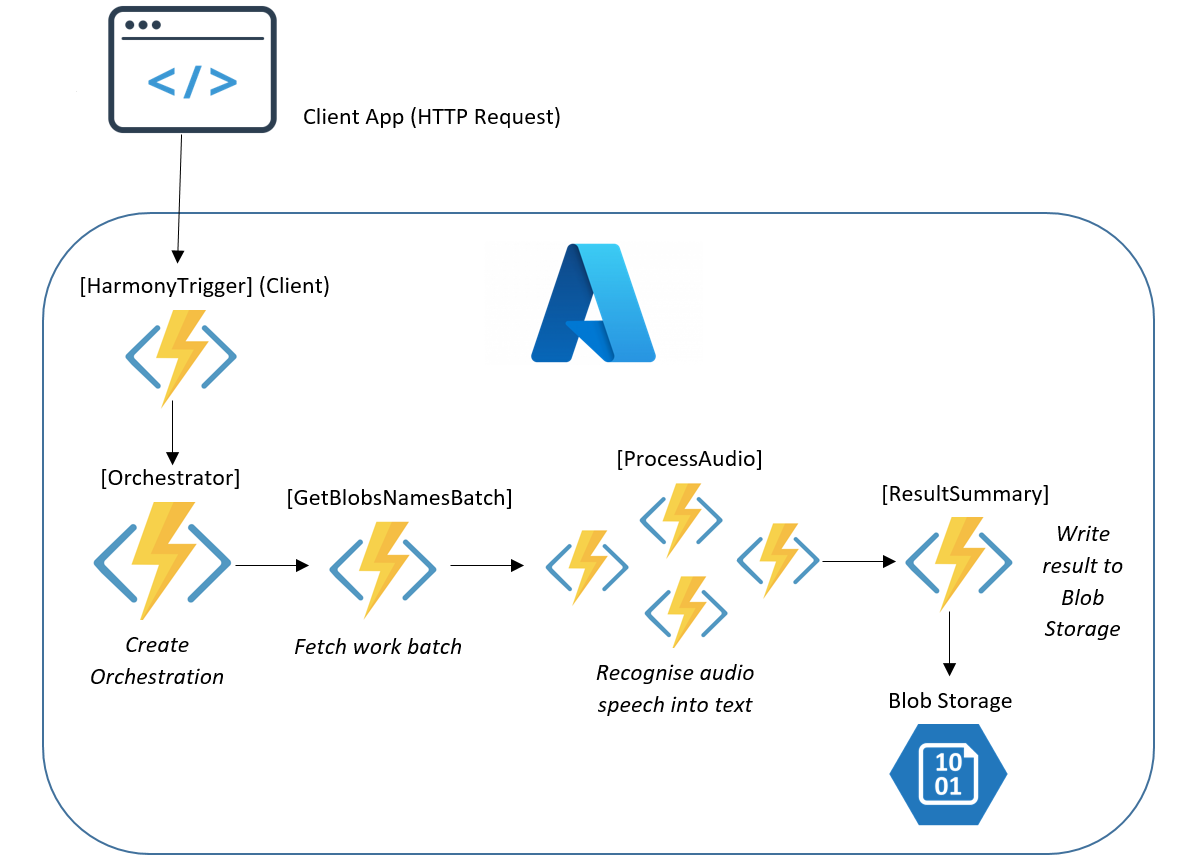
The Code
First, an HTTP request is sent to the Client Function by using the Function URL by a Client Application, in my case a web browser:
[FunctionName("HarmonyTrigger")]
public static async Task<IActionResult> HarmonyTrigger(
[HttpTrigger(AuthorizationLevel.Function, "get")] HttpRequest req,
[DurableClient] IDurableOrchestrationClient starter)
{
//start the orchestration
string id = await starter.StartNewAsync("Orchestrator", null);
return new OkObjectResult($"Sit back and chill, the orcherstration {id} started");
}The Client Function is triggered by the web browser request and calls the Orchestrator Function. This Orchestrator Function's job is to collect the batch of work items or jobs. The batch in this case contains all the filenames of the .wav audio files from the Azure blob storage container.
The Orchestrator Function then creates (and manages) an "orchestra" 🎼 of worker Activity Functions that first collect the batch of items ("GetBlobNamesBatch"), and then process the items in the batch by creating multiple instances of the worker Activity Function ("ProcessAudio"):
[FunctionName("Orchestrator")]
public static async Task Orchestrator(
[OrchestrationTrigger] IDurableOrchestrationContext context, ILogger log)
{
var parallelTasks = new List<Task<string>>();
// in orchestrator Function, only log if durableOrchestrationContext is not replaying.
//prevents this log being logged multiple times which can be misleading
if(!context.IsReplaying) { log.LogInformation("Now running batcher.."); };
//get the batch from first Activity
List<string> batch = await context.CallActivityAsync<List<string>>("GetBlobNamesBatch", null);
foreach (string blobItemName in batch)
{
//process tasks in parallel with 2nd Activity and collect the results
Task<string> task = context.CallActivityAsync<string>("ProcessAudio", blobItemName);
parallelTasks.Add(task);
}
//wait for all results to come back
await Task.WhenAll(parallelTasks);
//aggregate the results
StringBuilder builder = new StringBuilder();
parallelTasks.ForEach(task => builder.AppendLine(task.Result + "\r\n"));
//do something with the aggregate result in final Activity
await context.CallActivityAsync("ResultSummary", builder);
}The Orchestrator Function will first call the batch collection GetBlobNamesBatch Activity Function here:
[FunctionName("GetBlobNamesBatch")]
public static async Task<List<string>> GetBlobNamesBatch([ActivityTrigger] string inputParam, ILogger log, [Blob("voice", FileAccess.Write, Connection = "AzureWebJobsStorage")] BlobContainerClient blobContainerClient)
{
//get list of filenames using blobcontainerclient input binding, from voice container
log.LogInformation("Getting blob names..");
return await blobContainerClient.GetBlobsAsync().Select(blob =>blob.Name).ToListAsync();
}Next, audio files are processed in parallel with the ProcessAudio Activity Function:
[FunctionName("ProcessAudio")]
public static async Task<string> ProcessAudio([ActivityTrigger] string blobItemName, ILogger log,
[Blob("voice", FileAccess.Write, Connection = "AzureWebJobsStorage")] BlobContainerClient blobContainerClient)
{
var speechConfig = SpeechConfig.FromSubscription("[YOUR_SPEECH_SERVICES_KEY]", "[REGION_OF_SPEECH_SERVICES_RESOURCE]");
Stream datastream = await blobContainerClient.GetBlobClient(blobItemName).OpenReadAsync();
var reader = new BinaryReader(datastream);
//my voice utterances were recorded at 44100Hz sampling rate, 16 bit depth in Stereo (2 channels)
var audioInputStream = AudioInputStream.CreatePushStream(AudioStreamFormat.GetWaveFormatPCM(44100, 16, 2));
var audioConfig = AudioConfig.FromStreamInput(audioInputStream);
var recognizer = new SpeechRecognizer(speechConfig, audioConfig);
//read the the stream as bytes, write to audioInputStream and recognise speech as text
byte[] readBytes;
do
{
readBytes = reader.ReadBytes((int)datastream.Length);
audioInputStream.Write(readBytes, readBytes.Length);
} while (readBytes.Length > 0);
var result = await recognizer.RecognizeOnceAsync();
log.LogInformation($"Speech heard:{result.Text}");
return result.Text;
}The ProcessAudio Function receives the name of the work item in the form of the name of the .wav file from the known Blob storage container (in my example the container is called "voice" in my storage account). The .wav file is read as Stream object and parsed in to a SpeechRecognizer object that is hydrated with an Audio Config (that is hydrated with the audio stream details) and a Speech Config (that is hydrated with details of the Speech Services resource in Azure).
As processing continues, the logs show something like this, with different instances of the ProcessAudio Activity running in parallel:
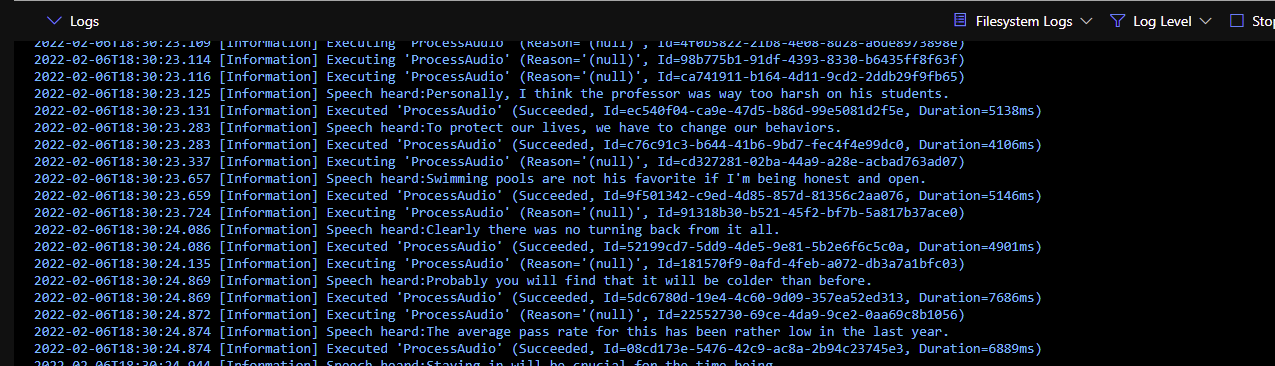
When all audio files are recognised and all text results are returned through the Orchestrator Function automatically managing the aggregation of the results, the aggregated result is sent to the final Function for processing, shown here as ResultSummary:
[FunctionName("ResultSummary")]
public static void ResultSummary([ActivityTrigger] StringBuilder builder, ILogger log, [Blob("outcontainer", FileAccess.Write, Connection = "AzureWebJobsStorage")] BlobContainerClient blobContainerClient)
{
//write the output texts to a new blob in a known container called outcontainer
log.LogInformation("Result was integer: " + builder.ToString());
blobContainerClient.UploadBlobAsync("TextOutput.txt", new MemoryStream(Encoding.UTF8.GetBytes(builder.ToString())));
}The Results!!

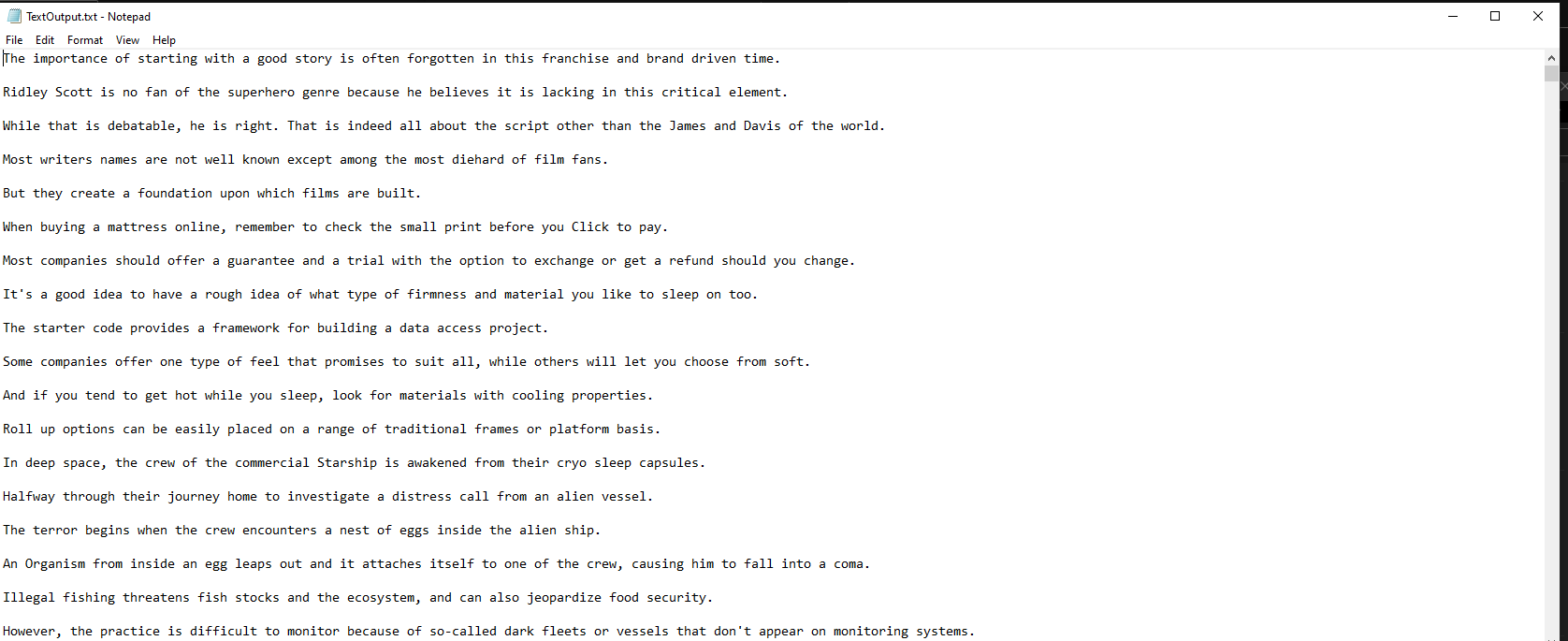
For Reference, my package versions are as follows:
<Project Sdk="Microsoft.NET.Sdk">
<PropertyGroup>
<TargetFramework>net6.0</TargetFramework>
<AzureFunctionsVersion>v4</AzureFunctionsVersion>
</PropertyGroup>
<ItemGroup>
<PackageReference Include="Azure.Storage.Blobs" Version="12.10.0" />
<PackageReference Include="Microsoft.Azure.WebJobs.Extensions.DurableTask" Version="2.6.0" />
<PackageReference Include="Microsoft.Azure.WebJobs.Extensions.Storage" Version="5.0.0" />
<PackageReference Include="Microsoft.CognitiveServices.Speech" Version="1.20.0" />
<PackageReference Include="Microsoft.NET.Sdk.Functions" Version="4.0.1" />
<PackageReference Include="System.Linq.Async.Queryable" Version="6.0.1" />
</ItemGroup>
<ItemGroup>
<None Update="host.json">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
</None>
<None Update="local.settings.json">
<CopyToOutputDirectory>PreserveNewest</CopyToOutputDirectory>
<CopyToPublishDirectory>Never</CopyToPublishDirectory>
</None>
</ItemGroup>
</Project>Now this makes it possible to to simply focus on recording a large amount of utterances without having to worry about writing them manually myself, as long I speak clearly with no background noise in my recordings, the Fan Out/Fan In Azure Function will be do that very efficiently for me 😃!! . When Functions work together like this, you can almost hear the harmony of it all!!
N.B Azure Speech To Text did have some difficulties on about 3 utterances and produced blank outputs, most likely because the recording quality was not the best at the time I recorded those ones. Might be an easy fix with a better recording environment with less echo on those entries!!!
(Cover Image Credit: Dan Hadar on Unsplash)