Voice AI for Blog sites with Azure OpenAI Service


To enable voice and read aloud speech capabilities for niche content websites, there is an abundance of Speech and Text services available from Azure OpenAI Service via Azure AI Foundry.
Here on Imaginarium, I've added AI speech to try to enrich the reading and learning experience for people who read the blog posts I write as I understand some people may have more questions on top of my topics that I wrote about. This AI Speech materialises in the form of three buttons that are populated with a randomly generated question that is based on the contents of the web page on Imaginarium. The user clicks a question, then an AI neural voice (currently from OpenAI) answers the question out loud.
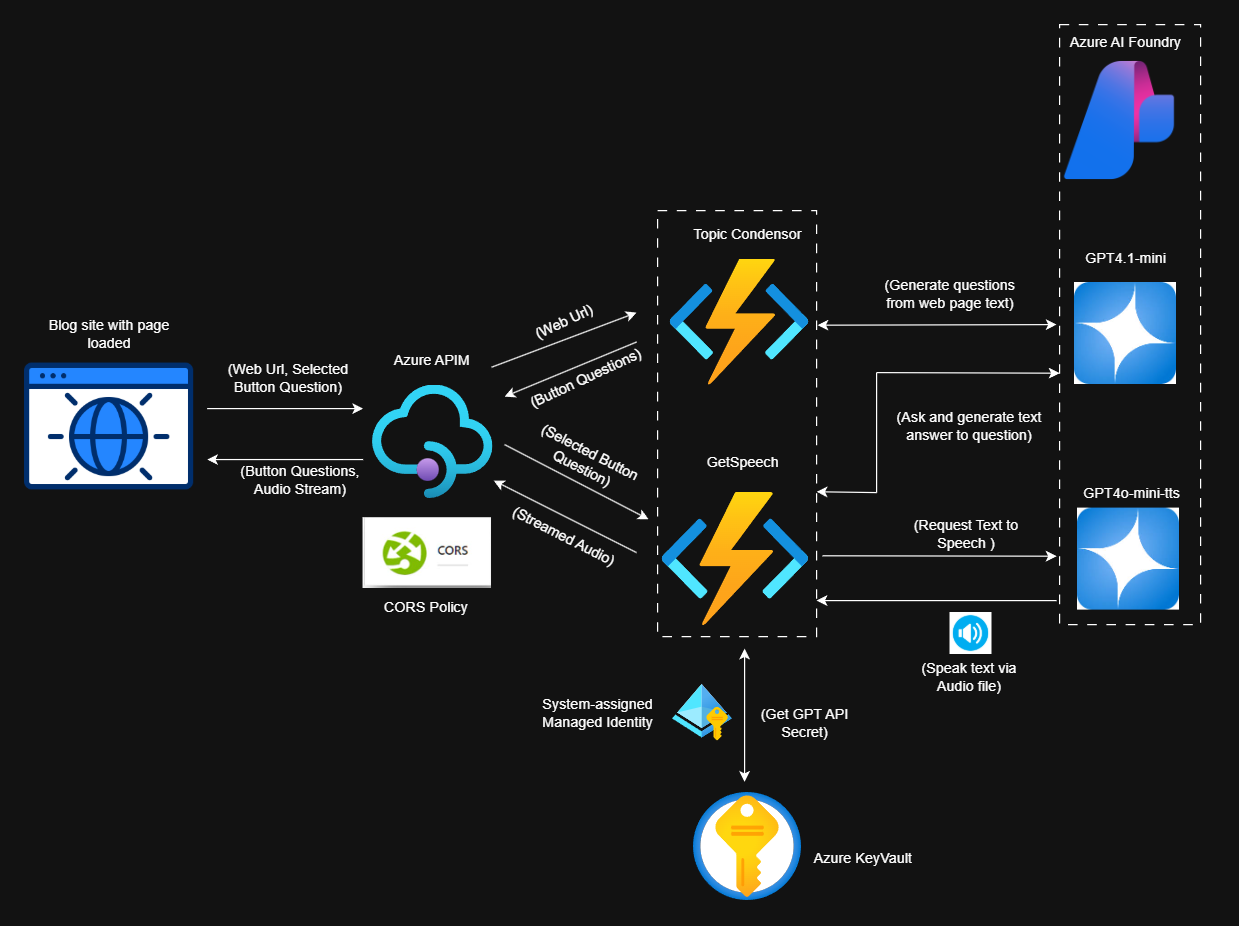
How does this all happen, and how do we make sure it is a quick and fluid experience? Below is an overview of the architecture of how this happens fast and securely.
Here is a demo of how responsive this process is when it talks back:
AI Voice responding back to generated question about web page
Embed AI Infused Buttons into Blog site
For Imaginarium, I embedded an HTML block (supported for the Ghost Blog Platform) into select posts of my choosing that you can see for example here and here, that display 3 buttons on screen.
The HTML section in the snippet file above holds three buttons with the three questions. The three questions are loaded through a process whereby code runs to send a request through to an Azure APIM instance with a CORS Inbound Policy for known domains, where an Azure Function is used as the backend to receive the currently loaded page URL. Within the Azure Function, we call onto an instance of GPT-4.1 mini (mini to minimise costs). This 'TopicCondensor' Function generates and sends back 3 questions to populate the buttons by responding through APIM and back on the browser:
[Function("TopicCondensor")]
public async Task<IActionResult> Run([HttpTrigger(AuthorizationLevel.Function, "post")] HttpRequest req)
{
string requestBodyStream = await new StreamReader(req.Body).ReadToEndAsync();
if (string.IsNullOrEmpty(requestBodyStream))
{
return new BadRequestObjectResult("Request body cannot be empty");
}
var aiData = JsonConvert.DeserializeObject<AIData>(requestBodyStream);
string gptApiKey = await GetGPTApiKey();
using var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("api-key", gptApiKey);
var requestUri = $"[GPT4.1mini_Endpoint_In_AzureAI_Foundry]";
var requestBody = new
{
//instruct the model with deliberate and careful prompting designed with the contents of the Azure blog in mind
messages = new[]
{
new { role = "system", content = "You are a helpful assistant taht helps users with Azure cloud computing and related topics." },
new { role = "user", content = $"Look and read this technical webpage/article and its contents: {aiData?.webUrl}, then I want you to craft your answer as strictly 3 seperate and SHORT questions (about 10 words max each) that a learner could theoretically ask based on your understanding of the web page" +
".Then shorten them for brevity as if they were flashcard questions. BE CREATIVE ABOUT THE QUESTIONS, Do not just rehash the main talking points, but ask further on a level or 2 beyond the webpage contents. DO NOT begin the questions with the words How or What. Assume that the learner is generally an intermediate to early expert in terms of their understanding of the topic already and has an Enterprise Azure mindset and is likely a Web Developer, System Architect, Product Manager or Tester. Structure the questions you pick in your reply here as Question1|Question2|Question3" }
},
temperature = 0.97, // boost creativity by getting closer to 1
max_tokens = 290 // helps with shortening AI Response
};
var json = System.Text.Json.JsonSerializer.Serialize(requestBody);
var content = new StringContent(json, Encoding.UTF8, "application/json");
var response = await httpClient.PostAsync(requestUri, content);
string responseString = await response.Content.ReadAsStringAsync();
Console.WriteLine(responseString);
var result = JsonConvert.DeserializeObject<OpenAiResponse>(responseString);
return new OkObjectResult(result.choices[0].message.content);
}Code to come up with useful questions that a learner can ask while reading a blog post
//Assuming we have enabled Managed Identity for the requesting Azure Function,
//plus GET persmissions for secrets through Access Policy
private async Task<string> GetGPTApiKey()
{
var keyVaultUrl = "[Your_keyvault_URI]";
//exponential backoff retry strategy
SecretClientOptions retryoptions = new SecretClientOptions()
{
Retry =
{
Delay= TimeSpan.FromSeconds(2),
MaxDelay = TimeSpan.FromSeconds(15),
MaxRetries = 8,
Mode = RetryMode.Exponential
}
};
var client = new SecretClient(new Uri(keyVaultUrl), new DefaultAzureCredential(), retryoptions);
KeyVaultSecret secret = await client.GetSecretAsync("[AIFoundryGPTEndpointKey]");
return secret.Value;
}
//generated classes, probably needs consolidation :D
public class AIData
{
public string webUrl { get; set; }
}
public class OpenAiResponse
{
public List<Choice> choices { get; set; }
}
public class Choice
{
public Message message { get; set; }
}
public class Message
{
public string content { get; set; }
}
public class TextInput
{
public string text { get; set; }
}Useful helper code
Return AI Voice in Web page
On clicking the button, the question text in the button is routed through Azure APIM again with a CORS Inbound Policy for permitted domain(s) for security, then forwarded onto a separate Azure Function that will execute 2 tasks. The first is to answer the question with a high quality model like GPT-4.1-mini in text. The output from the text-to-text query is then used to prompt a text to speech model such as GPT-4o-mini-tts to get the response as audio (talk back). This audio is strategically streamed back immediately as soon as data is available to the client to minimise the perception of latency:
[Function("GetSpeech")]
public async Task<IActionResult> GetSpeech([HttpTrigger(AuthorizationLevel.Function, "post")] HttpRequest req)
{
// Read input text from request body
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
if (string.IsNullOrWhiteSpace(requestBody))
{
return new BadRequestObjectResult("Request body cannot be empty");
}
var input = JsonConvert.DeserializeObject<TextInput>(requestBody);
if (input == null || string.IsNullOrWhiteSpace(input.text))
{
return new BadRequestObjectResult("Input text is required.");
}
// Step 1: Send text to GPT-4.1 for consolidation
string gptApiKey = await GetGPTApiKey();
string gptUri = "[GPT4.1mini_Endpoint_In_AzureAI_Foundry]";
var gptRequestBody = new
{
messages = new[]
{
new { role = "system", content = "You are a helpful assistant to answer questions you receive. Be creative in your answer and offer a note in the answer that might not be well known about that topic" },
new { role = "user", content = input.text }
},
temperature = 0.98, // boost creativity
max_tokens = 300
};
var gptJson = System.Text.Json.JsonSerializer.Serialize(gptRequestBody);
using var httpClient = new HttpClient();
httpClient.DefaultRequestHeaders.Add("api-key", gptApiKey);
var gptContent = new StringContent(gptJson, Encoding.UTF8, "application/json");
var gptResponse = await httpClient.PostAsync(gptUri, gptContent);
if (!gptResponse.IsSuccessStatusCode)
{
return new StatusCodeResult((int)gptResponse.StatusCode);
}
string gptResponseString = await gptResponse.Content.ReadAsStringAsync();
var gptResult = JsonConvert.DeserializeObject<OpenAiResponse>(gptResponseString);
string consolidatedText = gptResult?.choices?[0]?.message?.content;
if (string.IsNullOrWhiteSpace(consolidatedText))
{
return new BadRequestObjectResult("Failed to get consolidated text from GPT-4.1.");
}
// Step 2: Send consolidated text to gpt4o-mini-tts for audio output and stream it
string ttsApiKey = gptApiKey; // Use same key if applicable, otherwise replace
string ttsUri = "GPT4ominitts_Endpoint_In_AzureAI_Foundry]";
var ttsRequestBody = new
{
input = consolidatedText,
voice = "alloy", // or another supported voice, alloy is universally approachable
model = "gpt-4o-mini-tts"
};
var ttsJson = System.Text.Json.JsonSerializer.Serialize(ttsRequestBody);
using var ttsClient = new HttpClient();
ttsClient.DefaultRequestHeaders.Add("api-key", ttsApiKey);
var ttsContent = new StringContent(ttsJson, Encoding.UTF8, "application/json");
// Chunked response to start reading data as soon as available
var ttsResponse = await ttsClient.SendAsync(new HttpRequestMessage(HttpMethod.Post, ttsUri) { Content = ttsContent }, HttpCompletionOption.ResponseHeadersRead);
if (!ttsResponse.IsSuccessStatusCode)
{
return new StatusCodeResult((int)ttsResponse.StatusCode);
}
var audioStream = await ttsResponse.Content.ReadAsStreamAsync();
// Return a FileStreamResult to stream the audio back to the client
return new FileStreamResult(audioStream, "audio/mpeg")
{
FileDownloadName = "speech.mp3"
};
}Azure Function Code to answer the button question in text and speak back the answer
Conclusions
This functionality is available on a select number of posts here on Imaginarium where I believed could invoke further questions from a learner/reader. The initial implementation was laggy due to an unrefined response from the TTS model. This process was initially 'heavy' primarily due to the use of a larger model than necessary, which used the standard tts-hd model from OpenAI rather than a lighter gpt-4o-mini-tts. Additionally the audio was longer than needed to be useful to listen to , and was being transported synchronously which meant each requested waited for the whole file to be brought back (very bad user experience!!!). This was overcome through chunking the response and streaming the file back to the browser client. Overall these additional refinements meant:
🚀Faster audio playback of AI voice after clicking button (from 21seconds to 2.5 seconds )
💸Cost savings on general inferencing by switching to distilled OpenAI models
Other Considerations
I thought about using smaller open source models (Phi4 and Llama 3.2 8b specifically) and hosting them within Azure Container Apps to perhaps leverage 'more free' inference. However, my local testing proved that these models work but they were very repetitive on the questions that populate the buttons. Using Azure Container Apps would have also meant that to get better performance, I would have need to increase compute resources which defeats the purpose of having 'free' inference open source models😟!! Better to use lightning quick and cheap state of the art models in this case.