Azure Media Services Clips


Following the Azure Video Indexer indexing Insights I was able to produce from a podcast on a weekly schedule previously, I decided to go further into how this Insights JSON data can be utilised in a helpful way following my previous Summary (discussed here), such as using Azure Media Services to clip certain parts of the audio.
With the Insights JSON data we can do things such as:
- Organise the entire podcast into topics (in this case, discussions of abstract topics and discussions about people) 📚
- Clip these discovered topics into separate topic clips by where they appear in the podcast timeline 📎
- Merge (also known as muxing) clips of the same topic into individual files 🔗
- Listen to the separate merged topic audio files externally (discussed in next blog post with a Google Actions on a Google Nest Hub) 📡🎵
The first 3 points can be visualised as the following:
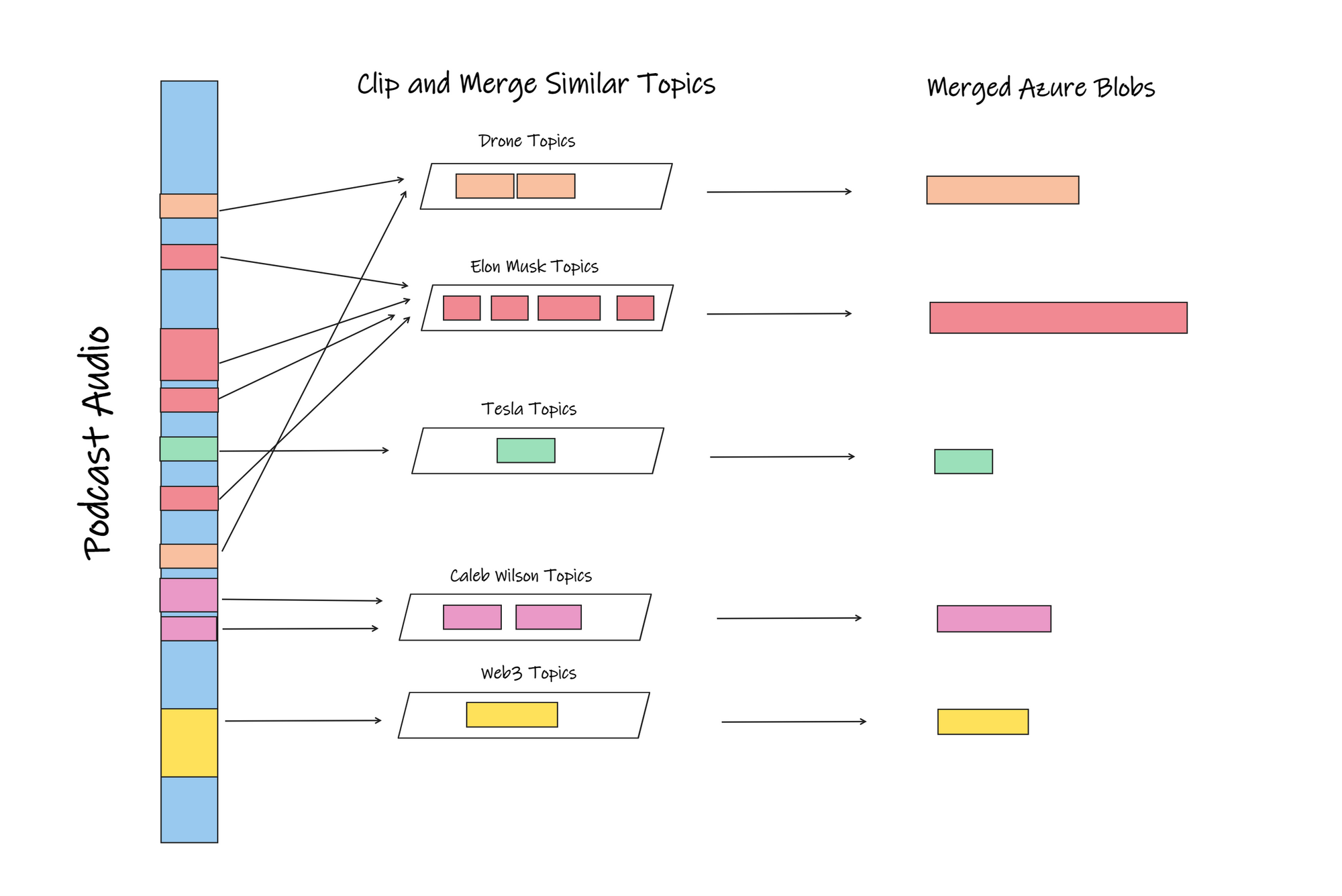
In this post, I talk about about how first 3 points above can be achieved where we already have the insights JSON, with Azure Media Services, an Event Triggered Azure Function, an Azure Storage Table and Azure Blob Storage.
Organising the podcast topics
After retrieving the index result JSON (either using the Video Indexer APIs or downloading the insights from our Video Indexer account), we can extract the discovered topics from the 'summarizedInsights' object and extract them based on our needs:
//pass in your json Index Result here to
//collect topics and people discussed
public List<ResultTopic> CollectResultTopics(string indexResult)
{
//quick but slightly more expensive deserialization
dynamic rawdata = JsonConvert.DeserializeObject(indexResult);
var topics = rawdata.summarizedInsights.topics;
var people = rawdata.summarizedInsights.namedPeople;
var duration = rawdata.summarizedInsights.duration.time;
//list of problematic characters to not use in topicnames
//for downstream processes
List<string> forbiddenCharacters = new List<string>();
forbiddenCharacters.Add("/");
forbiddenCharacters.Add("\\");
forbiddenCharacters.Add("[");
forbiddenCharacters.Add("]");
forbiddenCharacters.Add("(");
forbiddenCharacters.Add(")");
forbiddenCharacters.Add("*");
List<ResultTopic> resultTopics = new List<ResultTopic>();
foreach (var item in topics)
{
//60pc confidence for general topics is relatively good
if (item.confidence.Value >= 0.6)
{
foreach (var appearance in item.appearances)
{
//15s is reasonable minimum time for a topic
//and don't allow problematic characters in topicnames
if (appearance.endSeconds - appearance.startSeconds >= 15
&& forbiddenCharacters.Any(s =>
((string)item.name).Contains(s)) == false)
{
resultTopics.Add(new ResultTopic() { topicName =
SanitiseTopicName((string)item.name),
StartTime = appearance.startTime, EndTime = appearance.endTime });
}
}
}
}
foreach (var item in people)
{
//85pc confidence threshold for people, and must be notable people
if (item.confidence.Value >= 0.85 && item.referenceId != null)
{
foreach (var appearance in item.appearances)
{
//because the Indexer can allocate a small
//timespan for a discovered person or topic, adding extra
//buffer time on both sides of the clip
//is a good way to capture extra audio
var desiredStart = TimeSpan.Parse((string)appearance.startTime)
.Subtract(TimeSpan.FromSeconds(10));
string desiredEnd = "";
if (TimeSpan.Parse((string)appearance.endTime)
.Add(TimeSpan.FromSeconds(50)) < TimeSpan.Parse((string)duration.Value))
{
desiredEnd = TimeSpan.Parse((string)appearance.endTime)
.Add(TimeSpan.FromSeconds(50)).ToString();
}
else
{
desiredEnd = appearance.endTime;
}
//don't add a person's discussion more than 3 times
if (resultTopics.Where(x => x.topicName ==
((string)item.name)).Count() <= 3)
{
//do not allow problematic characters in topicnames
if (forbiddenCharacters.Any(s =>
((string)item.name).Contains(s)) == false)
{
resultTopics.Add(new ResultTopic() {
topicName = SanitiseTopicName((string)item.name),
StartTime = desiredStart.ToString(),
EndTime = desiredEnd.ToString() });
}
}
}
}
}
return resultTopics; //collection of ResultTopics
}public class ResultTopic
{
public string topicName { get; set; }
public string StartTime { get; set; }
public string EndTime { get; set; }
}
public string SanitiseTopicName(string name)
{
StringBuilder sb = new StringBuilder(name);
sb.Replace("-", "");
sb.Replace(".", "");
sb.Replace(",", "");
return sb.ToString();
}From the above code, we do the following:
->Only collect 'Topics' mentioned in the audio where the Indexer has at least 60 percent or more confidence that it heard that particular being talked about. And if the duration of the occurrence of that topic is more than 15s, then collect it.
->Only collect audio sections where 'People' of interest are talked about where the Indexer is at least 85 percent confident or more and where the person of interest has an external Reference (a notable person). For audio sections of people, add extra buffer of 10s before the Person is identified by the Indexer and add 50s to where the Indexer marks as the end of discussing that Person. This buffer time is to help us pick extra audio from the podcast host in case the Indexer was too narrow in selecting where a discussion about a person starts and ends.
->Only add up to 3 occurrences of discussions about a specific person in the collection with the desired Start and End times
Clip and merge similar topics into individual files
With the list of chosen result Topics and their known occurrence timestamps, we can add each occurrence into a JobInputSequence's list of Inputs. Each JobInputSequence acts as the JobInput for each topic we want to generate with Azure Media Services:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Net.Http;
using System.Text;
using System.Threading;
using System.Threading.Tasks;
using System.Xml;
using Microsoft.Azure.Management.Media;
using Microsoft.Azure.Management.Media.Models;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.WebJobs.Extensions.DurableTask;
using Microsoft.Extensions.Logging;
using Newtonsoft.Json;
//......
//pass the collection of ResultTopics and
//the full podcast's publicly accessible Url
public async Task<string> ClipSegments(List<ResultTopic> resultTopics,
string podcastAudioPublicUrl)
{
//MediaServiceControl is a custom class shown below this snippet
//for creating a Media Services Client object and a Transform
var mediaServicesClient = await MediaServiceControl.CreateMediaServicesClientAsync();
await MediaServiceControl.GetOrCreateTransformAsync(
mediaServicesClient,"[YOUR_RESOURCE_GROUP]",
"[YOUR_RESOURCE_GROUP]", "[TRANSFORM_NAME]");
var groupedTopics = resultTopics.GroupBy(s => s.topicName).Select(x => x).ToList();
foreach (var topic in groupedTopics)
{
Asset seedAsset = new Asset();
seedAsset.Container = SanitiseString(topic.Key) + $"-{Guid.NewGuid():N}";
JobInputSequence inputSequence = new JobInputSequence();
inputSequence.Inputs = new List<JobInputClip>();
foreach (var topicInstance in topic)
{
//each jobinput is a start and endtime of a topic occurrence
//within the full-length podcast audio
JobInputHttp jobInput = new JobInputHttp(files: new[] { podcastAudioPublicUrl },
start: new AbsoluteClipTime(TimeSpan.Parse(topicInstance.StartTime)),
end: new AbsoluteClipTime(TimeSpan.Parse(topicInstance.EndTime)));
inputSequence.Inputs.Add(jobInput);
}
Asset outputAsset = await mediaServicesClient.Assets.CreateOrUpdateAsync(
"[YOUR_RESOURCE_GROUP]", "[YOUR_AMS_INSTANCENAME]",
SanitiseString(topic.Key) + $"-{Guid.NewGuid():N}", seedAsset);
JobOutput[] jobOutput = { new JobOutputAsset(outputAsset.Name) };
await mediaServicesClient.Jobs.CreateAsync(
"[YOUR_RESOURCE_GROUP]",
"[YOUR_AMS_INSTANCENAME]",
"[TRANSFORM_NAME]",
"job1" + $"-{Guid.NewGuid():N}",
new Job
{
Input = inputSequence,
Outputs = jobOutput,
});
}
return "complete";
}
public static string SanitiseString(string name)
{
StringBuilder sb = new StringBuilder(name);
sb.Replace("-", "");
sb.Replace(".", "");
sb.Replace(" ", "");
return sb.ToString().ToLower();
}The MediaServiceControl class defined below is a custom helper class I made for wrapping the code that manages the creation of a Media Services Client and creating the Job Transform. The Transform used is a Built-in preset that creates good quality AAC audio at 192kbps. Note that the AACGoodQualityAudio preset in fact creates an mp4 file with no video track and audio only:
using System.Threading.Tasks;
using Microsoft.Azure.Management.Media;
using Microsoft.Azure.Management.Media.Models;
using Microsoft.Rest;
using Microsoft.IdentityModel.Clients.ActiveDirectory;
using Microsoft.Rest.Azure.Authentication;
//.....
public class MediaServiceControl
{
//get credentials to using AMS
public static async Task<IAzureMediaServicesClient> CreateMediaServicesClientAsync()
{
var credentials = await GetCredentialsAsync();
return new AzureMediaServicesClient(credentials)
{
SubscriptionId = "[YOUR_AZURE_SUBSCRIPTION_ID]",
};
}
//the domain can be found from the AMS instance properties
private static async Task<ServiceClientCredentials> GetCredentialsAsync()
{
ClientCredential clientCredential = new ClientCredential(
"[YOUR_SERVICE_PRINCIPAL_CLIENTID]",
"[YOUR_SERVICE_PRINCIPAL_CLIENTSECRET]");
return await ApplicationTokenProvider.LoginSilentAsync("[YOUR_DOMAIN]",
clientCredential,
ActiveDirectoryServiceSettings.Azure);
}
public static async Task<Transform> GetOrCreateTransformAsync(
IAzureMediaServicesClient client,
string resourceGroupName,
string accountName,
string transformName)
{
// reuse existing transform if it exists already or create a new one
Transform transform = await client.Transforms.GetAsync(
resourceGroupName,
accountName, transformName);
if (transform == null)
{
//settings for an AAC audio only output
TransformOutput[] output = new TransformOutput[]
{
new TransformOutput(
new BuiltInStandardEncoderPreset(EncoderNamedPreset.AACGoodQualityAudio),
onError: OnErrorType.StopProcessingJob,
relativePriority: Priority.High
)
};
transform = await client.Transforms.CreateOrUpdateAsync(resourceGroupName,
accountName, transformName, output);
}
return transform;
}
}Ultimately, as each AMS JobOutput is encoded, our Azure Media Services instance creates the output as a container in blob storage that contains the new audio file. The new audio file is not publicly accessible by default and that is what we discuss next to solve.
Consume the topic audio files externally
When the output files are created (ie when AMS finishes each encode output), we need to store a usable public URL for each topic that our consumer/client will be able use to listen to the audio. In my case, my Azure Media Services Instance is wired in Azure to send an Event to a separate Azure Function (shown below as the Function 'WriteSasUrlToStorage' ) whenever an encode is finished. (I wrote how this wiring can be done from the Azure Portal here under the Azure Media Services Instance's Event settings).
Each encode output finished triggers one Event. Each encode output represents one topic/person of interest. The Azure Function will write to an existing empty Azure Storage Table, with the resulting topic name and the publicly accessible blob Url to the audio as a Shared Access Signature Url that has Read Permissions for 8 hours. This Event Triggered Function looks like this:
using System;
using Microsoft.Azure.WebJobs;
using Microsoft.Azure.EventGrid.Models;
using Microsoft.Azure.WebJobs.Extensions.EventGrid;
using Microsoft.Extensions.Logging;
using System.Threading.Tasks;
using Azure.Storage.Blobs;
using Microsoft.Azure.Management.Media;
using Microsoft.Azure.Management.Media.Models;
using Newtonsoft.Json;
using Microsoft.Azure.Cosmos.Table;
using CloudTable = Microsoft.Azure.Cosmos.Table.CloudTable;
using TableOperation = Microsoft.Azure.Cosmos.Table.TableOperation;
using TableResult = Microsoft.Azure.Cosmos.Table.TableResult;
using System.Linq;
using CloudTableClient = Microsoft.Azure.Cosmos.Table.CloudTableClient;
//..... function class encapsulation here
[FunctionName("WriteSasUrlToStorage")]
public static async Task WriteSasUrlToStorage(
[EventGridTrigger] EventGridEvent eventGridEvent, ILogger log)
{
log.LogInformation("Starting to write to Azure Table storage");
var mediaServicesClient = await MediaServiceControl.CreateMediaServicesClientAsync();
var assetname = JsonConvert.DeserializeObject<EventRoot>(eventGridEvent.Data.ToString())
.output.assetName;
//Locate the created AMS output folder/container
Asset createdAsset = await mediaServicesClient.Assets.GetAsync("[YOUR_RESOURCE_GROUP]",
"[YOUR_AMS_INSTANCENAME]",
assetname);
var connection = Environment.GetEnvironmentVariable("AzureWebJobsStorage");
var container = new BlobContainerClient(connection, createdAsset.Container);
var blobs = container.GetBlobs();
//get the largest file from the generated outputasset folder -- the merged topic file
var datafile = blobs.OrderByDescending(x => x.Properties.ContentLength).FirstOrDefault();
BlobClient blobClient = container.GetBlobClient(datafile.Name);
//allow an 8 hour access period for that particular blob
var blobSASURL = blobClient.GenerateSasUri(Azure.Storage.Sas.BlobSasPermissions.Read,
DateTime.UtcNow.AddHours(8).ToUniversalTime());
//create a table entity
PodcastSasUrlItem entity = new PodcastSasUrlItem();
entity.PartitionKey = "Podcast";
entity.RowKey = container.Name.Split("-")[0];
entity.topicAudioSasUrl = blobSASURL.ToString();
//write to an existing Azure Storage Table
CloudStorageAccount storageAcc = CloudStorageAccount.Parse(connection);
CloudTableClient tblclient = storageAcc.CreateCloudTableClient();
CloudTable cloudTable = tblclient.GetTableReference("PodcastclipsSASUrls");
TableOperation insertOperation = TableOperation.InsertOrMerge(entity);
TableResult result = await cloudTable.ExecuteAsync(insertOperation);
log.LogInformation("wrote table item");
}
public class PodcastSasUrlItem : TableEntity
{
public string topicAudioSasUrl { get; set; }
}//Deserialisation classes for the above snippet
public class Output
{
public string assetName { get; set; }
}
public class EventRoot
{
public Output output { get; set; }
}Now that we have a place that can store the Urls of our newly clipped audio files, it means we are able to listen to them from different places (for up to 8 hours after they are made). But first we will need a way for our consumers to request what Urls they can have at that time. This can be done by an HTTP Triggered Function that will read all the records in the Azure Storage Table that we wrote the SAS Urls and return these to the requester:
//.... using statements the same as previous snippet above
[FunctionName("ServePodcastClips")]
public static List<PodcastResultItem> ServePodcastClips(
[HttpTrigger(AuthorizationLevel.Function,"get")] HttpRequestMessage req,
ILogger log)
{
List<PodcastResultItem> results = new List<PodcastResultItem>();
var connection = Environment.GetEnvironmentVariable("AzureWebJobsStorage");
//Connect to an existing table
CloudStorageAccount storageAccount = CloudStorageAccount.Parse(connection);
CloudTableClient tableClient = storageAccount.CreateCloudTableClient();
CloudTable table = tableClient.GetTableReference("PodcastclipsSASUrls");
//read all records in the Azure Storage Table and return as List
//to the client that made the request
TableQuery<PodcastSasUrlItem> query = new TableQuery<PodcastSasUrlItem>();
foreach (PodcastSasUrlItem entity in table.ExecuteQuery(query))
{
results.Add(new PodcastResultItem()
{
Topic = entity.RowKey,
AudioLocation = entity.topicAudioSasUrl
});
}
return results;
}public class PodcastResultItem
{
public string Topic { get; set; }
public string AudioLocation { get; set; }
}
public class PodcastSasUrlItem : TableEntity
{
public string topicAudioSasUrl { get; set; }
}Ok that's a lot to cover in one post!!!! In the next sister post, we hop on over to Google Action Builder and create our Action that can be triggered from a Google Nest Hub to call the above Azure HTTP Trigger and then play it back.
Post Cover Image Credit by Donald Giannatti / Unsplash